- US Dollar
- Register
- Log in
-
Shopping cart
(0)
-
You have no items in your shopping cart.
-

A good searchable PDF software should support Multilingual OCR. OCRvision's text recognition feature can detect a wide variety of languages and can detect multiple languages within a single scanned PDF. You can see the complete list of supported OCR languages here. This means you can successfully create a searchable PDF from a scanned PDF or scanned image with more than one language in it. OCRvision OCR software can be downloaded for free from our website.
In order to do Multilingual OCR using OCRvision, do the following steps;
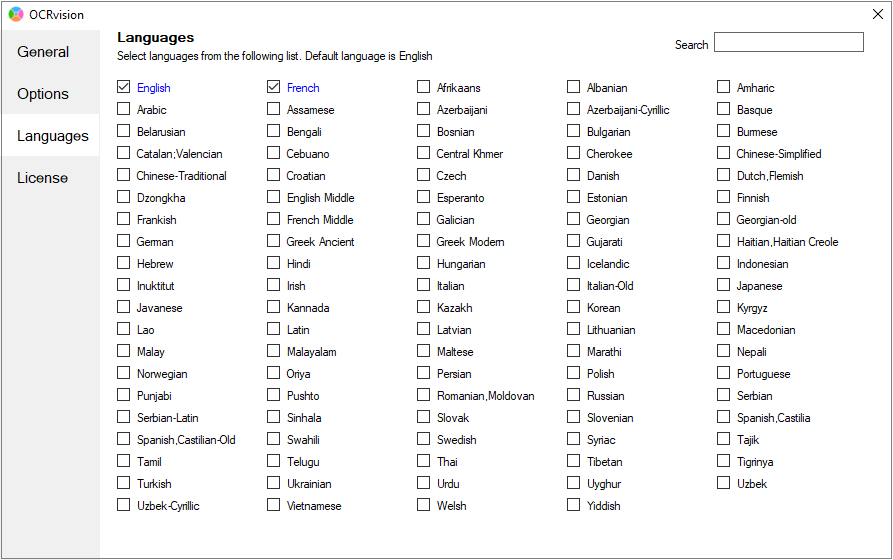
Fig 1: OCRvision language configuration interface
Click on the languages you want in your multi-language OCR process and check the tick box. Once a language is enabled the text will turn blue. If you want to disable the language you can uncheck the tick box. There is a search box on the right-hand side of the interface where you can search for a particular language.
Once you select and tick the language, it will automatically get updated and that language will be enabled for Multilingual OCR.
DONE. Now all you have to do is copy your scanned pdf document with multiple languages in the pre-configured "magic folder".
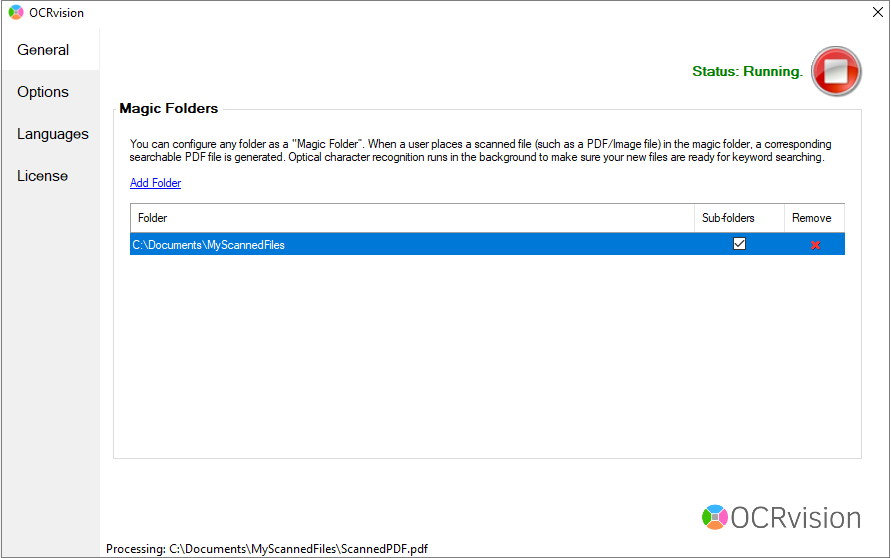
Fig 2: OCRvision magic folder configuration interface
After a couple of seconds, a searchable PDF with multiple languages will be generated in the magic folder automatically. You can see the "currently processing file" which is being converted to a searchable PDF in the bottom left notification strip as in the screenshot above. As I said earlier, You don't have to do any manual button click. OCRvision OCR software pdf is a searchable PDF OCR automation software. It will create a searchable PDF automatically.