- US Dollar
- Register
- Log in
-
Shopping cart
(0)
-
You have no items in your shopping cart.
-

Optical Character Recognition (OCR) technology plays a very crucial role in the digital transformation of the insurance industry. There are lots of benefits for the insurance industry in using OCR software and converting scanned PDFs to searchable PDFs. Insurance companies deal with lots of image documents that can be a scanned PDFs or email attachments in JPEG or PNG format. These image-based documents need to be processed and indexed on a regular basis. Traditionally insurance companies used to scan paper documents into PDF format and do manual indexing. This was done by manually tagging images with keywords in their document management system (DMS). This manual data entry was done by a person who analyses the document and manually types in keywords and creates a time-stamped folder structure. This method was highly inefficient, inconsistent, and time-consuming. This manual indexing may work for a small or medium company, but it can cause some delays in the workflow and immediate resolution of a claim for a big organization that is receiving thousands of documents on a daily basis.
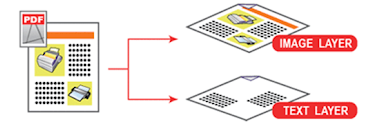
A typed or printed image is converted into a searchable PDF format using OCR PDF software. An OCR software can "recognize" the language and text data in an image. So when you apply OCR on a scanned PDF, it analyses the image, detects the text data, then adds this detected text as an invisible layer in the scanned PDF. This new form of "sandwich PDF" is text searchable. This new file format is known as a searchable PDF. Text from this invisible layer can be copied and indexed. So after OCR and searchable PDF conversion, information from your scanned PDFs will start appearing in your text search results.
Business decisions in an insurance company are based on the information available. Insurance companies generally invest lots of money in document management systems (DMS). But without OCR software in place, they are not fully utilizing the information available. There is a lot of information trapped inside scanned documents since the scanned content is not text searchable. This black box of data doesn’t have a text layer, so it can't be indexed by the search algorithm used by your document management system. Although you have invested big money and time in an awesome DMS, your employees are still taking hours manually searching for some information that can’t be found.
An effective OCR software can improve the accuracy of predictions and business decisions. Using batch OCR software, companies can convert large volumes of legacy documents into searchable PDFs. These searchable PDFs can be analyzed, and they can help the company to make faster and better decisions.
Using OCRvision software you can convert all your scanned PDFs into searchable PDFs. OCRvision works in the background and converts any newly added document to a searchable digital file. Please watch the video below for more details.