- US Dollar
- Register
- Log in
-
Shopping cart
(0)
-
You have no items in your shopping cart.
-
OCR stands for Optical Character Recognition. Nowadays OCR is a must-have technology for any business when it comes to dealing with scanned documents. OCR software is used by organizations to transform scanned documents into text-searchable PDFs. Without OCR software, it would be a very difficult and manual process to search through scanned documents. A good OCR software recognizes letters’ patterns and picks out text data from an image. This helps computers to read a scanned PDF in the same way that a human does. OCRvision is an auto OCR software with multi-language support.

PDF is a file format that is a machine or software-independent way of representing a digital document. But not all PDFs are the same. A PDF document can be created in different ways. You can export an existing word or excel document into PDF format, or you can create a brand-new PDF document using PDF editor software. These PDFs are called Native PDFs. In these documents, every character is represented in the metadata of the PDF file. This can be recognized by a computer. So, you can do a text search just like how you do in a word or excel file.
The second type of PDF is a scanned PDF. It is created by scanning a paper document using a scanner and saving it in PDF format. This is just a snapshot of a document. In the computer representation, there is no information regarding the characters in the document. It is just pixel data of an image. You cannot edit this scanned PDF just like a normal PDF or search for a particular word. Basically, a human can read this document, but a computer can only see the pixel information. It has no clue about the real characters inside this document.
A good OCR software helps in the visual recognition of characters in the scanned PDF and converts that document into an electronic character-based PDF file. This new format is popularly known as a searchable PDF or an OCR PDF.
When a human reads a document, our brain recognizes a character by analyzing the shapes and patterns of the visual input and comparing it against the pre-learned character set, like the alphabets of the English language. An OCR software is trying to do the exact same. An OCR software reads the pixel information from a scanned document image and compares it against the trained data.
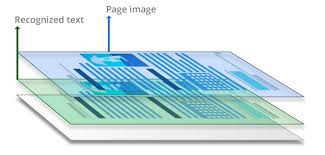 So A trained data helps the OCR software to recognize a pattern in an image and say what character it represents. When you run an OCR on a scanned document, the OCR software analyses the pixel and extracts the text information from this document. After this, the OCR software generates a new document by adding an invisible text layer on top of the scanned PDF. This new document can be read by a computer. This new format is called a searchable PDF or sandwich PDF.
So A trained data helps the OCR software to recognize a pattern in an image and say what character it represents. When you run an OCR on a scanned document, the OCR software analyses the pixel and extracts the text information from this document. After this, the OCR software generates a new document by adding an invisible text layer on top of the scanned PDF. This new document can be read by a computer. This new format is called a searchable PDF or sandwich PDF.
The answer to this question depends on different factors. The main factor is the quality of the scan. It is recommended that you scan the PDF at least 200 DPI. IF the quality of the scan is poor, it can make the images blurry and can affect the OCR accuracy. We have run an accuracy test using the same scanned PDF at 300 DPI and 50 DPI and accuracy was quite high in 300 DPI. Another factor is image alignment. While scanning the document make sure that the image is aligned perfectly with the horizontal line.
Yes, You can. OCRvision is an auto OCR software for windows. It can listen to a folder and OCR convert any scanned PDF to searchable PDFs automatically. OCRvision OCR software has multi-language support.
Please see the video below to get an idea about how to convert scanned PDF to searchable PDFs automatically.