- US Dollar
- Register
- Log in
-
Shopping cart
(0)
-
You have no items in your shopping cart.
-
A searchable PDF is a PDF file with text, that can be searched using the "search" functionality of a PDF reader software like Adobe Reader. In addition, this text can be selected and copied to another text editor program like Notepad.
Not all PDF files are searchable. If the PDF file is created with a PDF editor software, it contains text elements in page content streams of the PDF. But if a PDF is created by scanning a text document, there is no character/text information available. For a computer it is just pixel information about an image, ie an image of a text document is embedded within a PDF. So if you search for a word in a scanned PDF, you won't see any result.
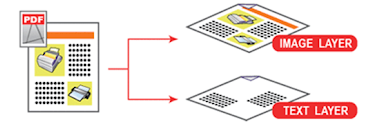 You have to do an extra step called Optical character recognition(OCR) to convert this PDF to searchable PDF. A searchable PDF is a scanned PDF with an invisible OCR text layer. This text layer is added by an OCR converter software. This OCR text layer can be searched and indexed.
You have to do an extra step called Optical character recognition(OCR) to convert this PDF to searchable PDF. A searchable PDF is a scanned PDF with an invisible OCR text layer. This text layer is added by an OCR converter software. This OCR text layer can be searched and indexed.
PDF or Portable Document Format is a file format introduced by Adobe to represent documents in a hardware/software/OS independent manner. So, each PDF document encapsulates the information like the text, fonts, graphics, images, and other information needed to display it.
You can broadly classify PDF documents into three;
Text-Based PDF
These are digitally created PDFs. We can call them “true PDFs”. Normally they are created using special software like Adobe Acrobat, Microsoft® Word, Excel®. You can even “print” a document as a PDF file. These documents are searchable. Just like the word documents you can edit, search and delete text from these documents.
Image-Based PDF
Image only or scanned PDF comes in the second category. These are created using scanners or digital cameras. It is basically an image embedded in a PDF document. Just like a JPEG or PNG file, they don’t have a text layer. That means you can only print them. You won’t be able to search for a text or copy text from these documents. If you are an organization dealing with lots of scanned documents, dealing with the data locked in these documents will be a big nightmare for you. You need to do OCR and convert this PDF to OCR PDF.
Searchable PDF (OCR PDF)
Searchable PDFs are created from image-based PDFs.OCR process converts an image-based pdf to a searchable PDF. As discussed above, the problem with the image-based document is that there is no text layer for you to search on.
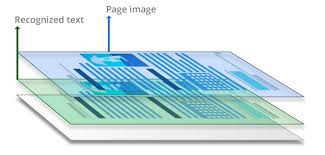
To solve this problem, we use Optical character recognition software like OCRvision. An OCR software will analyze the data in the image-based PDFs and “recognize” the text and add an invisible text layer to the document. This text layer is normally underneath the image. This text layer can be searched or indexed in your windows search. So, when you search for a keyword in this document, you are searching in this invisible text layer.
OCRVision is a searchable PDF OCR software that can automatically convert scanned PDFs in a folder to searchable PDFs. OCRvision can help you to create an automated OCR workflow for your scanned PDFs. Please watch the demo video below for more details.